
So, right now I'll probably be working from LIV, Lubotsky's Indo-Aryan lexicon, that Mallory and Adams book that I have, some Beekes, and possibly also Masatovic's Celtic etymological dictionary (which I'm pretty sure I also have).
Unfortunately, this does mean developing a lexicographic ontology, but I'm confident that I have enough experience for this. Basically, I'll start by putting thins in spreadsheets with the semantic data schema in mind, and then transform it to RDF.
Fortunately, Lubotsky's work is already tabular, and I spend a shit-ton of time on M&A so it really just needs page references. LIV is gonna be a lot of work though.
Unfortunately, this does mean developing a lexicographic ontology, but I'm confident that I have enough experience for this. Basically, I'll start by putting thins in spreadsheets with the semantic data schema in mind, and then transform it to RDF.
Fortunately, Lubotsky's work is already tabular, and I spend a shit-ton of time on M&A so it really just needs page references. LIV is gonna be a lot of work though.


Will you actually give PIE inflections (especially for the verbs) rather than everything found in Sanskrit this time?

This is a great time to plug the project I'm working on, then! I'm in my third semester of Greek, so I decided I wanted to make a set of Anki flashcards for every word in J. R. Cheadle's Basic Greek Vocabulary.
Then I realized that I wanted to put in etymology tags, since a Greek word is much easier to learn if it has a Latin or Sanskrit cognate.
Then I realized that that's a much bigger project than Anki can handle if I want it done thoroughly. So I'm creating a spreadsheet that will eventually become Greek Vocabulary for Philologists. It's essentially an etymological dictionary, plus cognates, for the first thousand to fifteen hundred words. After that, I might make Latin and Sanskrit versions...
Then I realized that I wanted to put in etymology tags, since a Greek word is much easier to learn if it has a Latin or Sanskrit cognate.
Then I realized that that's a much bigger project than Anki can handle if I want it done thoroughly. So I'm creating a spreadsheet that will eventually become Greek Vocabulary for Philologists. It's essentially an etymological dictionary, plus cognates, for the first thousand to fifteen hundred words. After that, I might make Latin and Sanskrit versions...


Will you attempt to standardise things this time round, Morrígan? Like, transcription, and probably inflection classes (as no-one seems to entirely agree, at least on the verbs)
Here's the link to the spreadsheet. Slow going. In a fit of optimism, there are Latin and Sanskrit sheets which will eventually be worked on. I might edit the permissions so that it's more of a collaborative project, once I've entered in all the words in A Basic Greek Vocabulary.
quoting KathAveara, Baroness of United Kingdom:Will you attempt to standardise things this time round, Morrígan? Like, transcription, and probably inflection classes (as no-one seems to entirely agree, at least on the verbs)
I did try last time; I had 3000 roots taken from 3 different sources and relatively few inconsistencies. I'll be modeling each source separately, and then linking all of them to create a single source with provenance back to the original document; this model should make it easier to find overlaps.
dhok: looks good, would be easy to work with too, to convert it to RDF, other than the entries that have the second line of forms.
quoting Morrígan, Baroness:quoting KathAveara, Baroness of United Kingdom:Will you attempt to standardise things this time round, Morrígan? Like, transcription, and probably inflection classes (as no-one seems to entirely agree, at least on the verbs)
I did try last time; I had 3000 roots taken from 3 different sources and relatively few inconsistencies. I'll be modeling each source separately, and then linking all of them to create a single source with provenance back to the original document; this model should make it easier to find overlaps.
dhok: looks good, would be easy to work with too, to convert it to RDF, other than the entries that have the second line of forms.
I'm thinking about how to make it more useful...what languages should I draw cognates from? I should probably add a column for the root, and then use the "etymology" column to elaborate on it...
Yeah, I would advise adding the root for sure; a lot of cognates may not be necessary if we approach this whole thing with the intent of plugging dictionaries together.
Rather than working on LIV heavily, I may switch back to converting the Mallory and Adams data I already have; that contains a fair amount of cognate data itself. Preserving provenance is important, so if you include cognates, I would suggest having a way to indicate which text, and page made the claim.
Rather than working on LIV heavily, I may switch back to converting the Mallory and Adams data I already have; that contains a fair amount of cognate data itself. Preserving provenance is important, so if you include cognates, I would suggest having a way to indicate which text, and page made the claim.
How would you prefer to set up the principle parts of verbs? For adjectives and nouns you only need two or three forms to know for certainly how they decline, but for Greek verbs you need six, and it's not just a problem of endings. It should be easier with Latin (four forms for verbs, two for nouns, three for adjectives), but for Sanskrit it becomes much more difficult- I don't think anybody has tried to create a principle part system for Sanskrit verbs; we'd be better off just making a digital version of Whitney's Roots, Verb-Forms, and Primary Derivatives of the Sanskrit Language.
Hah, yeah as far as Sanskrit goes, I agree.
I would either put them in a second workbook or move them somewhere else on the same line; otherwise it just becomes difficult to manage.
Also, this is like... half of one record from LIV. I gave up and badly need to think about my ontology design.
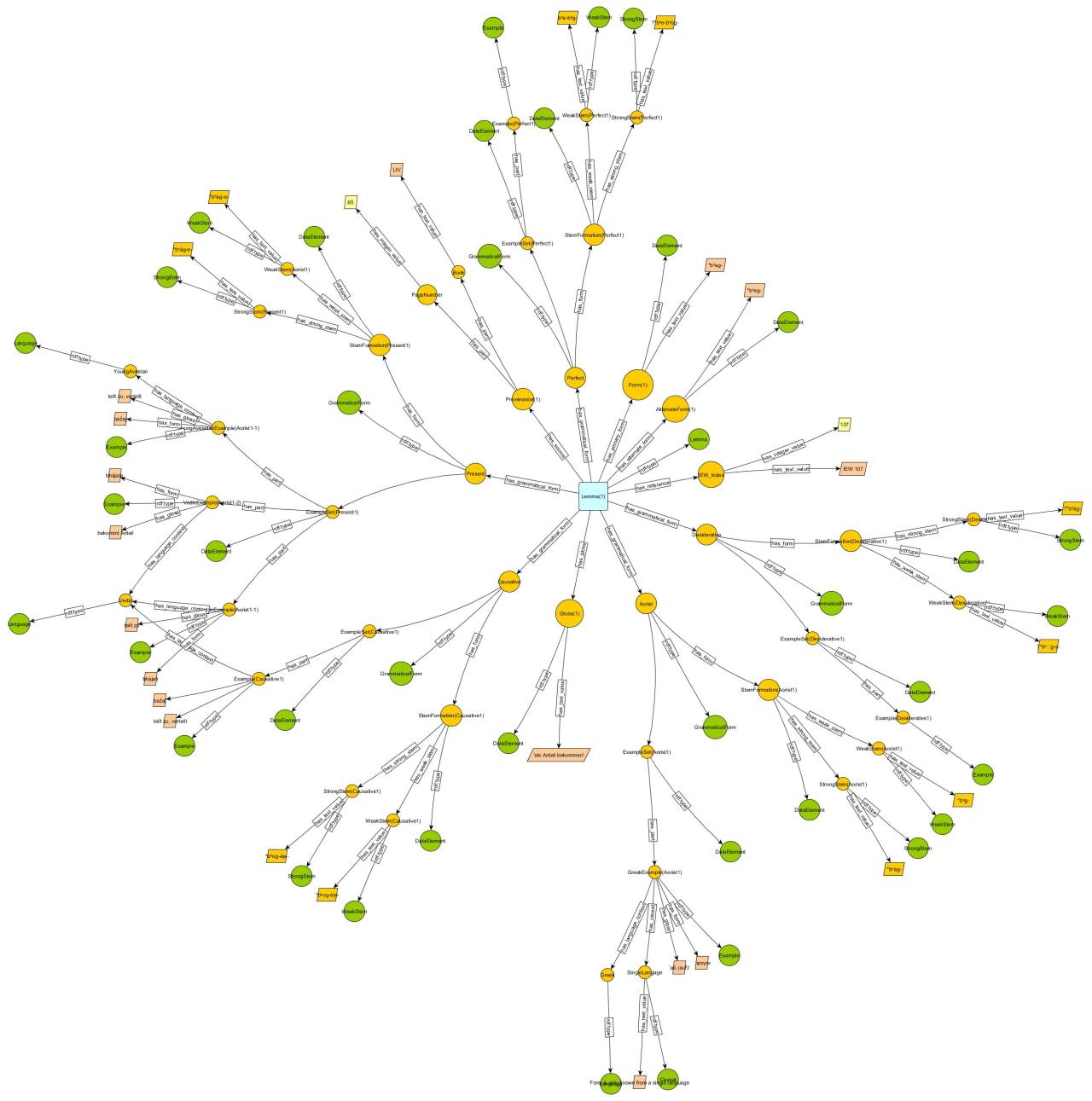
I would either put them in a second workbook or move them somewhere else on the same line; otherwise it just becomes difficult to manage.
Also, this is like... half of one record from LIV. I gave up and badly need to think about my ontology design.



Update on my end of the situation: I've finished the Anki deck through xi, about to start on omicron, and then I'll start back on the spreadsheet. I'm going to try and redo how I have it set up- possibly with a second sub-spreadsheet for principle parts. Instead of doing each word completely, I'll put in the head words and their definitions first, so that we have a clearer idea of what words are going to be used.
I think that's how I'm going to approach LIV. I'll do the headwords and glosses first, and then go back and do the grammatical forms, examples, and then finally footnotes.
I have started going through Mallory and Adams again and making a few corrections to what I have, adding page numbers, and a few notes that I was missing. Also trying to go for a consistent way of representing cognate forms, so that they can be easily processed using regular expressions.
I have started going through Mallory and Adams again and making a few corrections to what I have, adding page numbers, and a few notes that I was missing. Also trying to go for a consistent way of representing cognate forms, so that they can be easily processed using regular expressions.